Samstag, 5. Juli 2008 0:21
Dieser Text ist »etwas« älter, ich hatte ihn am 15. Februar 2005 auf einer inzwischen nicht mehr verfügbaren Homepage veröffentlicht. Die geäußerten Gedanken erscheinen mir aber immer noch als wertvoll und wichtig, deshalb diese erneute Veröffentlichung.
Unabhängig von den Feinstrukturen der »Wörter« im Voynich-Manuskript lassen sich harmonische Regeln für die Folge der Glyphen in einem »Wort« feststellen. Diese Regeln sind verhältnismäßig einfach, wurden aber vom Autor im gesamten Manuskript angewandt. Beim Betrachten dieser Regeln kommen Zweifel daran auf, dass es sich beim Voynich-Manuskript um niedergeschriebene Sprache im gewöhnlichen Sinn des Wortes handeln kann.
 Ich werde mich für die folgenden Darlegungen des Transkriptions-Systemes EVA bedienen, die »Wörter«, Glyphen und Glyphfolgen werden zur leichteren Erkennung in fetter Schrift gesetzt. Für Wortzählungen habe ich die vollständige Transkription von Takeshi Takahashi verwendet.
Ich werde mich für die folgenden Darlegungen des Transkriptions-Systemes EVA bedienen, die »Wörter«, Glyphen und Glyphfolgen werden zur leichteren Erkennung in fetter Schrift gesetzt. Für Wortzählungen habe ich die vollständige Transkription von Takeshi Takahashi verwendet.
Jemand, der sich längere Zeit mit dem Voynich-Manuskript beschäftigt, bekommt eine gewisse Intuition dafür, dass die Reihenfolge der Glyphen in einem Wort sehr festen Regeln folgt. Es kann nicht jede Glyphe an jeder Position stehen – bestimmte Glyphfolgen wirken auf der Stelle »falsch«.
Zunächst fällt ein erkennbares System von Präfixen und Suffixen auf. Das typische »Wort« im Manuskript beginnt mit q-, qo- oder o- und endet mit Glyphenfolgen aus einer recht großen Auswahl, in welcher die Gruppen -in, -ir, -il, -es und -dy besonders auffällig hervorstechen. Diese offensichtlichen Strukturmerkmale führten des öfteren zur Annahme, dass es sich hierbei um durchschimmernde Spuren einer Grammatik mit Flexionsystem handeln müsse – allerdings hat diese Annahme noch nicht bei der Identifikation der Sprache geholfen.
Ich möchte diesen vielbetrachteten Aspekt einmal außer Acht lassen und auf die zeichnerische Harmonie der Glyphfolgen eingehen.
Nach einigen Monaten des ernsthaften Forschens wird jedem Menschen intuitiv klar, dass es sich bei der Glyphenfolge qoteody um ein mögliches »Wort« handelt. Dieses »Wort« erscheint dann auch zwölf Mal im Manuskript – es ist damit eines der nicht besonders häufigen Worte, so dass diese »Klarheit« nicht (wie etwa beim sehr häufigen qoteedy) aus der Erinnerung kommen kann. Ebenso ist intuitiv klar, dass die Glyphenfolge qoteidy, die ja transkribiert auf dem ersten Blick sehr ähnlich aussieht, ein sehr ungewöhnliches »Wort« wäre. Und tatsächlich, dieses »Wort« kommt im Manuskript nicht vor.
Aber was unterscheidet diese Glyphenfolgen? Welches Bildungsgesetz für die »Wörter« nimmt man hier intuitiv auf, so dass man oft recht zielsicher entscheiden kann, ob ein bestimmtes »Wort« möglich ist oder nicht?
Die Beantwortung dieser Frage führt auf ein Harmoniegesetz für die aufeinanderfolgenden Glyphen, welches auch das beobachtete Suffixsystem auf natürliche Weise hervorbringt. Doch um dieses zu erkennen, muss man sich von den Transkriptionen abwenden und dem Schriftbild des Manuskriptes zuwenden. Zur besseren Erläuterung habe ich eine Grafik mit den hier postulierten Glyphenklassen und ein paar Beispielen in diese Seite eingefügt und die Glyphen der EVA-Transkription gegenübergestellt.
Die grundlegenden Glyphenklassen
Wenn man die Glyphen in den Bildern des Manuskriptes sorgfältig untersucht, stellt man schnell fest, dass der Glyphenvorrat relativ einfach aufgebaut ist. Es lassen sich drei Klassen von Glyphen an Hand ihres ersten Striches unterscheiden, dem zur Differenzierung in die speziellen Glyphen verschiedenste Dekorationen hinzugefügt werden können. Diese Reihenfolge beim Zeichnen der Glyphen lässt sich an vielen Stellen des Manuskriptes bestätigen, da durch das Absetzen der Feder Lücken in der Glyphe entstehen und häufig nach dem Absetzen die Feder in die Tinte getaucht wurde, so dass der folgende Strich dunkler erscheint.
Neben diesen drei Klassen gibt es noch zwei wichtige Ausnahmezeichen – leider kümmert sich die Wirklichkeit nicht immer um das analytische Streben nach Vereinfachung. Schon jetzt sei gesagt, dass eine dieser Ausnahmen für die »Wortbildung« im Rahmen der beobachteten Harmoniegesetze von Bedeutung ist.
Die nur an vereinzelten Stellen auftretenden »weirdos« werden hier nicht behandelt, fügen sich jedoch manchmal gut in das System ein. Manchmal allerdings auch nicht.
Die i-Klasse: Der erste Strich aller Glyphen dieser Klasse ist ein kurzer Abwärtsstrich, der um etwa 30 Grad gegen die Vertikale nach links geneigt ist. Beim EVA-Zeichen i wird die Glyphe nur von diesem Strich gebildet, darüber hinaus gibt es die wichtigen Glyphen n, r, l und m, die mit diesem Strich beginnen und ihm eine Verzierung hinzufügen.
Die e-Klasse: Der erste Strich dieser Klasse ist ein ungefähr halbkreisförmiger Bogen, dessen Anfang ähnlich geneigt ist wie der Abwärtsstrich der i-Klasse. Bei den EVA-Zeichen e, c und h wird die Glyphe nur von diesem Stich gebildet, darüber hinaus gibt es in dieser Klasse die wichtigen Glyphen o, d, s, y und die wegen ihrer Seltenheit als »weirdos« zu betrachtenden g und b.
Die Gallows: Der erste Strich dieser Klasse ist ein deutlich über der Scheiblinie angesetzter, strikt vertikaler Abwärtsstrich, dem immer eine weitere Dekoration hinzugefügt wird. Der Strich tritt also niemals allein als Glyphe auf. In diese Klasse gehören die EVA-Zeichen k, t, f und p, ferner sind einige der »weirdos« auf diese Art gebildet.
Die Ausnahmeglyphen
Wie schon erwähnt, gibt es genau zwei Glyphen, die aus diesem einfachen Schema der drei Klassen herausfallen. Beide scheinen wichtige Funktionen im Manuskript zu erfüllen, und eine dieser Ausnahmen (das a) ist entscheidend für die Aufrechterhaltung des später beschriebenen Harmoniegesetzes.
Die q-Glyphe: Diese Glyphe tritt nur am Anfang eines »Wortes« auf. Sie besteht aus einem strikt vertikalen Abwärtsstrich, der aber im Gegensatz zu den Glyphen der Gallow-Klasse auf Höhe der Schreiblinie angesetzt wird und diese Linie nach unten hin deutlich durchbricht. Am oberen Ende dieses Striches wird eine nach links gewandte gerade Linie im Winkel von ungefähr 45 Grad angesetzt, diese wird bis zur Mitte des Schreiblinienbereiches fortgesetzt und dort horizontal, aber leicht nach oben weisend abgeknickt. Die sehr häufig folgende Glyphe o wird mit diesem Horizontalstrich verbunden, so dass in diesem Fall der Eindruck einer Ligatur entsteht.
Die a-Glyphe: Diese Glyphe entsteht aus der Kombination (oder Ligatur) des Bogens der e-Klasse mit dem Abwärtsstrich der i-Klasse. Ihre besondere Bedeutung für die Harmoniegesetze wird an späterer Stelle klar werden.
Die Ligaturen
Es gibt einige sehr bemerkenswerte Glyphenfolgen, die einen starken Eindruck von Ligaturen erwecken und deshalb an dieser Stelle (mit allen Vorbehalten wegen des unbekannten Schriftsystemes) auch so genannt werden, die sich aber fast alle mit einer (relativ seltenen, aber sehr wichtigen) Ausnahme zwanglos in das System einfügen. Die häufigsten Formen seien hier kurz aufgelistet – es gibt aber darüber hinaus vereinzelt sehr komplexe Formen von drei oder mehr Glyphen sowie Ligaturen mit den Glyphen o und y.
Ligaturen der e-Klasse
Die folgenden Ligaturen fügen sich durch den ersten Strich zwanglos in die e-Klasse ein und werden im Folgenden auch so behandelt.
Die ch-Ligatur: Dies sind einfach zwei e-Glyphen, die am oberen Ansatzpunkt durch eine deutliche, strikt horizontale Linie verbunden sind.
Die sh-Ligatur: Sie entspricht der ch-Ligatur, enthält jedoch als zusätzliche Verzierung einen Bogen auf oder über der horizontalen Linie. Die Form dieses Bogens ist so variabel, dass immer wieder die Frage aufgeworfen wurde, ob sie nicht Information tragen könnte. Für die Betrachtung der »harmonischen Wortbildung« spielt diese Frage jedoch keine große Rolle.
Gemischte ie-Ligatur
Die ih-Ligatur: Dies ist die einzige Ligatur dieser Klasse und die zuvor benannte wichtige Ausnahme. Sie sieht der ch-Ligatur sehr ähnlich, aber das erste Zeichen ist der einfache Strich der i-Glyphe. Diese Ligatur tritt nur in dieser Reihenfolge auf, es gibt keine ci-Ligatur. Aus den späteren Darlegungen wird deutlich werden, dass eine hypothetische ci-Ligatur im Rahmen der Harmoniegesetze nicht erforderlich ist und daher wohl auch nicht auftritt.
Ligaturen mit eingebetteten Gallows
Die ch- und ih-Ligaturen (und die gelegentlichen ähnlich gebildeten Ligaturen mit o oder y) können ein eingebettetes Zeichen der Gallow-Klasse enthalten, welches die horizontale Linie kreuzt (cfh, cph, ckh, cth, ifh, iph, ikh und ith). Diese Kombination sieht dann so aus, als würde die Gallow-Glyphe auf einer Art von Podest stehen. Das Auftreten dieser Ligaturen ist sehr rätselhaft und einer umfassenden Betrachtung in einem eigenen Text würdig.
Und damit ist auch alles erklärt, was zum Verständnis der Harmoniegesetze erforderlich ist. Wer sich von den ausführlichen Erläuterungen zu den Zeichenklassen etwas »erschlagen« fühlt, sollte noch einmal einen Blick auf meine kleine Grafik werfen – manchmal sagt ein Bild wirklich mehr als tausend Worte. Alles in allem sollten die Kriterien für die Zuordnung einer Glyphe zu einer Klasse und die Bewertung einer Ligatur jetzt so klar sein, dass sie von jedem Leser verstanden und in einer Analyse angewendet werden können. Dabei ist auch für die meisten (aber natürlich nicht für alle) »weirdos« eine eindeutige Zuordnung zu einer dieser Klassen möglich. Für die wichtigsten Weirdos sei dies hier vorweggenommen:
»Weirdos« der i-Klasse: sind j und eventuell auch z, dessen Glyphe durch den strikt horizontalen ersten Strich zwischen den Gallows und der i-Klasse steht und den starken Eindruck eines zu klein geratenen k macht.
»Weirdos« der e-Klasse: sind b und eventuell u, dessen Glyphe allerdings zusammen mit der a-Glyphe eine Klasse bilden müsste, wenn sie häufiger wäre. Der Eindruck der Glyphe ist der einer Ligatur aus e und n.
»Weirdos« ohne mögliche Zuordnung: sind v und x – in beiden Fällen ist der »normale« Aufbau der Glyphen verlassen worden, die Zeichen scheinen aus einem völlig anderem Zusammenhang in dieses Manuskript geraten zu sein.
Die sieben Harmoniegesetze
Jetzt sind endlich alle Definitionen vorhanden, um die sieben Harmoniegesetze für die Glyphenfolge im Voynich-Manuskript zu postulieren. Verglichen mit den Erläuterungen im Vorfelde sind sie sehr einfach und kurz, die Reihenfolge spiegelt die Wichtigkeit der Gesetze (also den Mangel an Ausnahmen) wider.
Erstes Harmoniegesetz: Die e-Folge – Auf eine Glyphe der e-Klasse folgt eine weitere Glyphe der e-Klasse, eine ch-Ligatur, ein Gallow oder eine a-Glyphe.
Zweites Harmoniegesetz: Die i-Folge – Auf eine i-Glyphe folgt eine weitere Glyphe der i-Klasse oder eine Ligatur der ih-Klasse.
Drittes Harmoniegesetz: Der i-Abschluss – Eine Glyhpe der i-Klasse, die keine i- oder l-Glype ist, beendet in der Regel ein »Wort«.
Viertes Harmoniegesetz: Vermeidung »nackter« Abschlüsse – Ein »Wort« endet niemals mit einer »nackten« i- oder e-Glyphe, sondern immer mit einem komplexeren Zeichen aus diesen Glyphenklassen.
Fünftes Harmoniegesetz: Die l-Ausnahme – Die Glyphe l kann als Glyphe der e-Klasse verwendet werden, obwohl sie an sich eine Glype der i-Klasse ist.
Sechstes Harmoniegesetz: Der i-e-Wechsel – Wenn auf eine Glyphe der i-Klasse eine Ligatur der ih-Klasse folgt, wird das »Wort« mit Glyphen der e-Klasse fortgesetzt.
Siebentes Harmoniegesetz: Die e-Gallow Äquivalenz – Ein Gallow ist fast immer von Glyphen der e-Klasse umgeben oder in eine Ligatur der ih-Klasse eingebettet.
Als leicht verständliche Zusammenfassung dieser Harmoniegesetze, ohne komplizierte Formulierung ausgedrückt, können die folgenden Punkte gelten:
- Auf i folgt i oder e in der Form ih.
- Auf e folgt e oder i in der Form a.
- l ist ein »Jokerzeichen«, das sowohl i als auch e sein kann.
- Die Gallows gelten als e.
Es sind genau diese sehr einfachen und für einen Großteil des Textes angewandten Regeln, die das Schriftbild des Voynich-Manuskriptes so ästhetisch ansprechend wirken lassen. Jeder Verstoß gegen diese Regeln fällt sofort optisch als ein »unpassendes Zeichen« auf. Wer das nicht glauben kann, besorge sich den Zeichensatz »EVA Hand 1″, installiere ihn und lasse einen beliebigen Text mit diesem Zeichensatz darstellen – vom harmonischen Schriftbild des Voynich-Manuskriptes ist das Ergebnis weit entfernt.
Was hat das zu bedeuten?
Natürlich schreit dieses Ergebnis danach, interpretiert zu werden. Es kann sich auf keinen Fall um einen Zufall handeln, dass konsequent Regeln zum Aufrechterhalten eines harmonischen Schriftbildes angewandt wurden. Es ist sehr schwierig, eine Seite im pflanzenkundlichen Teil zu finden, in der mehr als zwei bis drei »Wörter« eine Ausnahme von diesen Regeln bilden. Die häufigste Ausnahme ist übrigens der Wechsel von i nach o und von o nach i — und ich vermute inzwischen regelmäßig einen Transkriptionsfehler oder eine übersehene »Wortgrenze«, wenn ich letzteres in einer Transkription sehe. Manchmal ist der kleine Strich, der a und o voneinander unterscheidet, fast unsichtbar, und manchmal ist die Erkennung des Zwischenraumes zwischen den »Wörtern« sehr schwierig.
Ich hätte diese sehr häufige Ausnahme durch eine achte Harmonieregel abdecken können. Aber es lag mir viel daran, das Paradigma »auf i folgt i, auf e folgt e und der Wechsel geschieht über a und ih« so deutlich wie nur möglich werden zu lassen. Mit einer Ausnahmenhäufigkeit im Bereich der 2 Prozent kann ich bei diesem Postulat gut leben – wird es doch andererseits so stark bestätigt.
Dennoch, eine »harmonische« Regel für das Schriftbild ist verwunderlich.
Der Schreiber des Voynich-Manuskriptes hat bemerkenswert wenig auf Layout geachtet, er hat in der Regel keine Linien für die »Schrift« vorgezeichnet und so ein recht unregelmäßiges Schriftbild in Kauf genommen. Da nimmt es Wunder, dass diese rigiden »Wortbildungsgesetze« für optische Harmonie im Schriftbild sorgen – das passt einfach nicht gut zusammen.
Dies ist eine leichte Bestätigung für den Verdacht, dass es sich beim vorliegenden Manuskript um eine Abschrift handelt. Die Aussicht, dass der Abschreiber vielleicht ein Manuskript kopierte, das er selbst nicht verstand und dabei gewiss Fehler machte, ist für alle Entzifferungsbemühungen ein Albtraum.
Haben wir es mit einem »Text« zu tun?
Wenn jemand am Voynich-Manuskript forscht und dieses große Rätsel lösen will, so geschieht dies unter der Voraussetzung, dass es einen »sinnvollen Klartext« gibt, der wiederhergestellt und gelesen werden will. Ob man annimmt, es handele sich um eine geistreich ersonnene Verschlüsselung oder eine verloren gegangene Schrift einer unbekannten Sprache, spielt in diesen Bemühungen keine Rolle.
Doch würde bei der Notation oder Verschlüsselung eines sprachlichen Textes ein derartiges, auf optische Harmonie optimiertes Schriftbild entstehen? Mir erscheint das etwas fragwürdig.
Ich will damit nicht sagen, dass im Manuskript keine sinnvolle Botschaft enthalten ist. Ich will nur sagen, dass man den Geist für die Möglichkeit offen halten sollte, dass diese Botschaft nicht unbedingt in der Form eines Textes im gewöhnlichen Sinne des Wortes vorliegen muss – also als Folge von phonetischen Zeichen und Wörtern, die eine Sprache abbilden, so etwas, wie jetzt bei Ihnen gerade im Browser sichtbar ist.
Deshalb meine schnelle Hypothese einer sinnvollen Notation, die kein Text ist – und bei der die harmonischen Regeln sogar ein sinnvolles Feature wären: Das Manuskript könnte eine musikalische Notation einer Form von Musik sein, die nach relativ strengen Regeln komponiert wurde. Eine solche »Botschaft« ist vollkommen sinnvoll, und ihre Niederschrift ist (für Musizierende) sehr nützlich. Nur mit dem »Lesen« wird es natürlich nichts, vielleicht sollte man es einmal mit Singen ausprobieren.
Viele rätselhafte Eigenarten würden auf Grund dieser einfachen Idee erklärlich.
- Die deutlichen Strukturen, welche die Zeile des Manuskriptes als eine »Bedeutungseinheit« kennzeichnen, könnten die Zeile als eine musikalische »Bedeutungseinheit«, etwa eine Phrase erklären.
- Die starke Neigung des »Textes« zu Wiederholungen und leichten Abänderungen im nächsten »Wort« sind als musikalisches Stilmittel wirklich nicht ungewöhnlich. Ein kurzes Thema wird mehrfach, eventuell mit leichten Abwandlungen oder in einer anderen Tonhöhe wiederholt — ob im Kinderlied oder in einer komplexen Sinfonie.
- Die besonderen statistischen Eigenschaften der ersten Zeile eines »Absatzes« oder einer Seite könnten Besonderheiten zum Anfang einer musikalischen Komposition oder eines deutlich abgegrenzten Teiles einer solchen widerspiegeln.
- Die typischen Endungen der »Wörter« entsprechen bestimmten harmonischen musikalischen Wendungen oder bestimmten, für das Ende einer musikalischen Bedeutungseinheit typischen rhythmischen Mustern.
- Das hohe Maß an Ordnung, welches den »Text« des Manuskriptes prägt, findet sich in jeder »wohlklingenden« Musik. Ebenso findet sich ein gewisses Maß an Überraschung und Unordnung darin – ansonsten wird die Musik als »langweilig« empfunden.
- Die beiden »Currier-Sprachen« könnten den heutigen Tongeschlechtern Dur und Moll entsprechen – ich weiß allerdings nicht, ob sich diese zum Erstellungszeitpunkt des Manuskriptes bereits aus den mittelalterlichen Kirchentonarten als wichtige Tonleitern herausgebildet hatten.
- Das Scheitern aller bisherigen Versuche, den »Klartext« des Manuskriptes unter der Annahme einer sprachlichen Information wiederherzustellen, ist völlig verständlich. Es hat seine Ursache in einer falschen Annahme über die Beschaffenheit des Textes.
Auf Grund dieser Annahme kann die »optische Harmonie der Kursive« mit den hier dargelegten Harmonieregeln eine sinnvolle und vernünftige Eigenschaft sein. Es hätte sich jemand ein musikalisches Notationssystem ausgedacht, welches »wohlklingende« musikalische Stilelemente auch »gut aussehen« lässt. In unserer heutigen Notenschrift ist das gar nicht so sehr anders, krasse Dissonanzen wie der Gleichklang des Intervalles der Sekunde wirken in der Notation auffällig und tonartfremde Noten erfordern zusätzliche Zeichen, die in der Regel schon optisch klar machen, dass hier etwas »ungewöhnliches« erklingt.
Abschließendes
Ich erwarte nicht, dass ein einziger Forscher glücklich über diese etwas plumpe, zurzeit noch mit wenig »harten Daten« belegte Erklärung ist. Zu vieles bleibt dabei unerklärt, etwa die Natur der Illustrationen oder die Labels. Ich selbst werde ein wenig in dieser Richtung weiterforschen – aber ich bin selbst ein »ausgelernter Optimist« und glaube nicht an den großen Durchbruch nach einer einzigen guten Idee.
Fraglich bleibt es vor allem, warum es keinen anderen überlieferten Zeugen für ein derartiges Notationssystem geben sollte. Eine schnelle Erklärung wäre, dass auf diese Weise monophone (einstimmige) Musik notiert wurde – die im späten Mittelalter von der polyphonen (mehrstimmigen) Musik immer mehr abgelöst wurde. Das System verschwand, weil es nicht leicht an die neue »musikalische Mode« anzupassen war – und es begann der Siegeszug des heutigen Notensystemes. Diese geht in seinem Kern übrigens auch auf ein mittelalterliches Vorbild, die »Numensysteme« zurück.
Eines aber sollte jedem klar sein: Nach vielen Jahrzehnten der Forschung, mit vereinter Geisteskraft, großen Enthusiasmus und der verfügbaren Rechenleistung der Jetztzeit ist das Voynich-Manuskript immer noch vollkommen »unverstanden«. Dass es sich nicht um einen mittelalterlichen »Fake« handelt, steht für mich unter Berücksichtung der bekannten Fakten und der sehr fremdartigen Struktur des »Textes« außer Frage. Von daher sollte jeder in aller Ruhe prüfen, ob der Fehler nicht in den grundlegenden Annahmen der bisherigen Forschung liegen könnte. Wir alle wollen aus einer Folge von rätselhaften Glyphen jene Stimme aus dem späten Mittelalter hören, die ein so einzigartiges und rätselhaftes Werk geschaffen hat. Und warum sollte diese Stimme nicht singen?

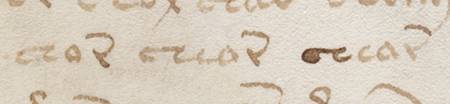
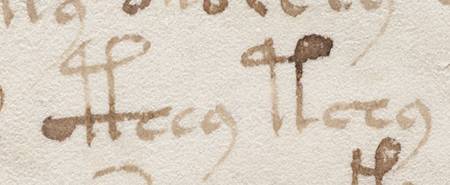

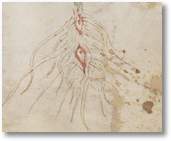 Doch ich schaute mir die relativ gewöhnlich aussehende Pflanze mit ihren enigmatischen, in roter Farbe gezeichneten »Wurzelaugen« noch einmal in aller Ruhe an. Dabei fiel mein Blick ganz unwillkürlich auch auf den Text, dessen Fluss im zweiten und dritten Absatz von den Blüten und Blütenstängeln unterbrochen wird.
Doch ich schaute mir die relativ gewöhnlich aussehende Pflanze mit ihren enigmatischen, in roter Farbe gezeichneten »Wurzelaugen« noch einmal in aller Ruhe an. Dabei fiel mein Blick ganz unwillkürlich auch auf den Text, dessen Fluss im zweiten und dritten Absatz von den Blüten und Blütenstängeln unterbrochen wird. Und dann fand ich es weiter etwas auffällig, dass eine »g«-artige Form mitten in einer Zeile auftritt. Ich bin es gewohnt, dass die besonderen Glyphen »m« und das viel seltenere »g« gehäuft am Ende einer Zeile auftreten, und ich habe mich schon oft gefragt, warum das so ist. Es ist ja für mich völlig klar, dass es eine Stuktur innerhalb der Zeilen gibt, die gewissermaßen die Wörter innerhalb einer Zeile »sortiert«, und ich weiß auch, dass jeder Versuch einer Entschlüsselung diese Erscheinung in Betracht ziehen sollte, aber ich kann mir immer noch keinen Reim darauf machen. (Vielleicht ist es auch eine formale Eigenart einer mir unbekannten Form der Lyrik…)
Und dann fand ich es weiter etwas auffällig, dass eine »g«-artige Form mitten in einer Zeile auftritt. Ich bin es gewohnt, dass die besonderen Glyphen »m« und das viel seltenere »g« gehäuft am Ende einer Zeile auftreten, und ich habe mich schon oft gefragt, warum das so ist. Es ist ja für mich völlig klar, dass es eine Stuktur innerhalb der Zeilen gibt, die gewissermaßen die Wörter innerhalb einer Zeile »sortiert«, und ich weiß auch, dass jeder Versuch einer Entschlüsselung diese Erscheinung in Betracht ziehen sollte, aber ich kann mir immer noch keinen Reim darauf machen. (Vielleicht ist es auch eine formale Eigenart einer mir unbekannten Form der Lyrik…)