Wenn es im Texte blüht
Nur, um einmal so eine kleine Sackgasse aufzuzeigen, in die man immer wieder rennt, wenn man sich mit dem Voynich-Manuskript beschäftigt…
Es kommt vor allem im pflanzenkundlichen Teil des Voynich-Manuskriptes immer wieder vor, dass der Text durch die Zeichnung einer Pflanze unterbrochen wird, wie zum Beispiel hier auf der Seite f17r:

Und jedes Mal, wenn ich versuche, mein unlesbares Lieblingsbuch zu »lesen«, kommt es vor, dass ich darin Dinge sehe, die sich bei einer genaueren Untersuchung in Nichts auflösen.
So auch heute.
Als ich die Seite f17r betrachtete, war ich eher am (mutmaßlich lateinischen) Text am oberen Rand dieser Seite interessiert, der mit den Worten »mallior allor« zu beginnen scheint und sich dann in die zunehmende Unlesbarkeit auflöst. Genau genommen, wollte ich nachschauen, ob dieser Text vom gleichen Schreiber geschrieben sein könnte, der auch den Text auf Seite f116v verfasste und ferner, ob es Ähnlichkeiten zwischen dieser Handschrift und der Handschrift der Monatsnamen im Tierkreis gäbe. Wie so oft, hat sich diese kleine Untersuchung in der Beliebigkeit solcher Interpretationen aufgelöst und kein »hartes« Ergebnis zutage gefördert.
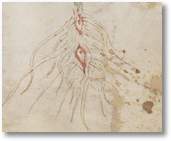 Doch ich schaute mir die relativ gewöhnlich aussehende Pflanze mit ihren enigmatischen, in roter Farbe gezeichneten »Wurzelaugen« noch einmal in aller Ruhe an. Dabei fiel mein Blick ganz unwillkürlich auch auf den Text, dessen Fluss im zweiten und dritten Absatz von den Blüten und Blütenstängeln unterbrochen wird.
Doch ich schaute mir die relativ gewöhnlich aussehende Pflanze mit ihren enigmatischen, in roter Farbe gezeichneten »Wurzelaugen« noch einmal in aller Ruhe an. Dabei fiel mein Blick ganz unwillkürlich auch auf den Text, dessen Fluss im zweiten und dritten Absatz von den Blüten und Blütenstängeln unterbrochen wird.
Und plötzlich glaubte ich, etwas Auffälliges zu sehen. Ausgerechnet auf einer Seite, auf der sogar die Wurzeln Augen bekommen haben, fiel mir ein eigentümlicher »Weirdo« auf, eine Mischung aus »d« und »g« in EVA, der in der vierten Zeile des Textes unmittelbar vor der Blüte auftaucht.
 Und dann fand ich es weiter etwas auffällig, dass eine »g«-artige Form mitten in einer Zeile auftritt. Ich bin es gewohnt, dass die besonderen Glyphen »m« und das viel seltenere »g« gehäuft am Ende einer Zeile auftreten, und ich habe mich schon oft gefragt, warum das so ist. Es ist ja für mich völlig klar, dass es eine Stuktur innerhalb der Zeilen gibt, die gewissermaßen die Wörter innerhalb einer Zeile »sortiert«, und ich weiß auch, dass jeder Versuch einer Entschlüsselung diese Erscheinung in Betracht ziehen sollte, aber ich kann mir immer noch keinen Reim darauf machen. (Vielleicht ist es auch eine formale Eigenart einer mir unbekannten Form der Lyrik…)
Und dann fand ich es weiter etwas auffällig, dass eine »g«-artige Form mitten in einer Zeile auftritt. Ich bin es gewohnt, dass die besonderen Glyphen »m« und das viel seltenere »g« gehäuft am Ende einer Zeile auftreten, und ich habe mich schon oft gefragt, warum das so ist. Es ist ja für mich völlig klar, dass es eine Stuktur innerhalb der Zeilen gibt, die gewissermaßen die Wörter innerhalb einer Zeile »sortiert«, und ich weiß auch, dass jeder Versuch einer Entschlüsselung diese Erscheinung in Betracht ziehen sollte, aber ich kann mir immer noch keinen Reim darauf machen. (Vielleicht ist es auch eine formale Eigenart einer mir unbekannten Form der Lyrik…)
Ich schaute mir daraufhin die anderen Wörter an, die dort stehen, wo der Textfluss durch die Pflanze unterbrochen wird. Es handelt sich um die Wörter »okchom«, »opdyg«, »cphaldy«, »chetey«, »zepchy«, »ykchy«, »chypcham«, »mdol« oder »ymdol« und »daiin«. Mit Ausnahme des recht gewöhnlichen »daiin« und des auch manchmal auftretenden »ykchy« sind dies in ihrer Überzahl sehr ungewöhnliche Wörter im Manuskripte.
Und deshalb war ich auf einmal »alarmiert«.
(Für jene, die sich jetzt wundern: Nach einigen Jahren Beschäftigung mit diesem »verdammten Manuskript« bekommt man ein sehr genaues Gefühl dafür, welche Wörter darin »ungewöhnlich« sind und muss kaum noch nachschlagen. Aber die Regeln, die man unbewusst wahrnimmt und die sich in diesem Gefühl verdichtet haben, lassen sich nur sehr schwierig in einer Weise formulieren, aus der sich ein Algorithmus für einen Computer machen lässt. Ich arbeite aber immer noch daran.)
Es erschien mir so, als würde der Umbruch des Textes durch eine Pflanze auf den Text rückwirken, als würde er »ungewöhnliche« Wörter »erzeugen«. Das war nun eine Erscheinung, die ich so noch nie wahrgenommen hatte und die einer kurzen Untersuchung würdig war.
Als erstes schrieb ich mir ein kleines Skript, das Wörter extrahiert und zählt, die vor dem Umbruch durch eine Pflanze auftauchen. Dieses Skript setzt die eingebetteten Kommentare voraus, wie sie in Jorge Stolfis interlinearem Archiv üblich sind. Mit Hilfe dieses Skriptes und meines Tools viat erzeugte ich dann eine Liste von Wörtern aus der vollständigen Transkription von Takeshi Takahashi, die im pflanzenkundlichen Teil vor einer Pflanzenzeichnung im Textfluss auftauchen. Die Kommandozeile dafür ist recht einfach:
viat -t H -i H | perl plantbreak.pl
Als Ergebnis der Ausführung des Skriptes entstehen zwei Dateien.
allstat.txt
In dieser Datei finden sich alle Wörter nach Häufigkeit sortiert, die im gesamten untersuchten Text erscheinen.bplant.txt
In dieser Datei finden sich die Wörter nach Häufigkeit sortiert, die vor einer gezeichneten Pflanze erscheinen.
Leider sind die ersten zwanzig Zeilen der »Wörter vor den Pflanzen« denn doch nicht mehr so alarmierend, sie sehen so aus:
62 daiin 50 dy 43 s 20 cthy 19 dal 17 dain 15 dam 14 oky 14 dar 13 ol 13 sy 13 aiin 12 d 10 y 9 dan 9 qoty 9 chy 8 chdy 8 or 8 chckhy
Das allgegenwärtige »daiin« ist auch hier an der Spitze. Aber immerhin zeigt sich hier doch eine etwas andere Verteilung von Wörtern als im normalen Textfluss:
474 daiin 234 chol 159 chor 159 s 141 dy 128 or 115 dar 112 shol 107 aiin 105 chy 98 cthy 96 sho 92 ol 85 dain 75 y 73 chey 70 shy 69 ar 67 chedy 67 shor
Die zunächst offenbare, andere Verteilung der Wörter relativiert sich aber schnell, wenn man einen Blick in das Manuskript wirft. Sehr häufig sind die Wörter vor einer Pflanze nämlich auch die letzten Wörter einer Zeile, und diese sind oft ungewöhnlich. (Vor allem häufen sich hier die auf »m« endenden Wörter, ganz so, als sei dieses »m« eine Abkürzung, die verwendet wird, wenn der Raum auf dem Pergament eng wird.)
Dennoch habe ich ein weiteres Experiment angehängt, da ich einmal wissen wollte, wie sich die Endglyphen auf die Wortlisten verteilen. Auch hierfür verwende ich wieder ein sehr einfach gestricktes Skript.
Bei der Wortliste mit allen Wörtern des pflanzenkundlichen Teiles sieht die Verteilung auf die Endglyphen so aus:
a 30 0.26% c 2 0.02% d 234 2.06% e 45 0.40% f 11 0.10% g 40 0.35% h 39 0.34% i 2 0.02% k 26 0.23% l 1666 14.66% m 370 3.26% n 1840 16.19% o 491 4.32% p 11 0.10% r 1894 16.67% s 497 4.37% t 28 0.25% x 1 0.01% y 4138 36.41%
Die gleiche Liste für die Wörter vor den Pflanzen zeigt einige charakteristische Abweichungen:
a 5 0.44% d 55 4.85% e 1 0.09% f 1 0.09% g 4 0.35% h 9 0.79% i 1 0.09% k 1 0.09% l 140 12.35% m 72 6.35% n 202 17.81% o 19 1.68% r 76 6.70% s 87 7.67% t 2 0.18% y 459 40.48%
Am augenfälligsten ist dabei vielleicht die doppelt so hohe Häufigkeit der Glyphen »m« und »d«, die im ähnlichen Umfang erhöhte Häufigkeit der Glyphe »s« und das etwas häufigere »y«. Es ist also etwas »anders« vor den Pflanzen, und dies lässt sich schon mit sehr einfachen Mitteln aufzeigen.
Aber so lange sich dieser Effekt mit den Effekten am Zeilenende überlagert, ist er für sich zu wenig aussagekräftig. Ich werde allerdings noch weitere Experimente in dieser Richtung machen und mir einmal anschauen, ob sie irgendwohin führen…

Dienstag, 10. März 2009 21:43
[…] spricht. Aber Ernst bei Seite, ich habe heute zum ersten Mal bemerkt, dass im Voynich-Manuskript ungewöhnliche Wörter gehäuft auftreten, wenn der fließende Text von einer …, habe diese Erscheinung aber noch nicht genau genug gefasst, dass ich sie näher untersuchen […]
Mittwoch, 18. März 2009 18:07
hallo! ich weiß leider noch nicht allzu viel über die thematik. nach dem studium zahlreicher beiträge im netz erscheint es mir jedoch immer unwahrscheinlicher, dass nur ein einzelner algorithmus hinter der ganzen sache steckt. da ich beruflich am rande mit informatik-problemen konfrontiert werde, würde ich einen ontologischen ansatz empfehlen, bin jedoch fachlich auch nicht in der lage hier hilfe bereitzustellen. vielleicht findet sich aber irgendwo ein informatiker der genaue ratschläge geben kann. alle bisherigen erkenntnisse und regeln ließen sich damit abbilden und würden durch interferenz maschinen-logisch weiterverarbeite werden können. ein allgemeiner einstieg unter http://de.wikipedia.org/wiki/Ontologie_(Informatik)