Zu den Transkriptionen
Jeder, der heute am Voynich-Manuskript forschen möchte, hat einen erheblichen Vorteil gegenüber vielen früheren Forschern: Es stehen mehrere Transkriptionen großer Teile des Manuskriptes zur Verfügung, und es gibt hervorragendes Bildmaterial. Der größte Teil des Manuskriptes kann in Form von hochaufgelösten Bildern betrachtet werden, und zu jeder Seite existiert mindestens eine Transkription. Zudem ist eine erhebliche Menge existierender historischer und aktueller Transkriptionen im interlinearen Archiv von Jorge Stolfi zusammengestellt und kann mit Leichtigkeit verglichen werden.
(Einen ersten Eindruck der im interlinearen Archiv verfügbaren Transkriptionen kann man zum Beispiel im Voynich Information Browser erhalten – und wer ein wenig Analyse machen will, kann sich auch interessierende Teile extrahieren lassen.)
Ich selbst verwende übrigens für schnelle Überprüfungen meiner (sich meist schnell als haltlos herausstellenden) Annahmen die vollständige Transkription von Takeshi Takahashi aus dem interlinearen Archiv. Anfangs habe ich dies noch eher unkritisch getan, aber später musste ich bemerken, dass es sich um eine durchaus gute Wahl gehandelt hatte. Obwohl Takahashi als Grundlage seiner Mammutarbeit nur gering aufgelöstes und qualitativ schlechtes Bildmaterial zur Verfügung hatte, erweisen sich viele seiner Lesungen auch beim Vergleich mit hochauflösenden Bildern als sehr gut, der Anteil fragwürdiger oder sicher falscher Entscheidungen in der Transkription liegt nach meinen Stichproben zwischen drei und fünf Prozent. Eine Schwäche hat allerdings die Transkription von Takahashi, und das sind die astrologischen und kosmologischen Diagramme. Die Texte in den Ringen enthalten außerordentlich viele Fehler. Da ich mich meist auf Absätze (und meist im pflanzenkundlichen Teil) konzentriere, spielt diese Fehlerquelle für mich keine so große Rolle, aber wer selbst tätig werden will, sollte das wissen.
Viele andere verfügbare Transkriptionen sind schwächer, selbst die ebenfalls sehr gute Transkription von Currier. Andere Transkriptionen, vor allem die Übertragung bestimmter Einzelseiten durch Jorge Stolfi, erwecken bei einem gründlichen Vergleich mit guten Bildern den Eindruck, dass hier eher die von Jorge Stolfi erkannten Muster als die Wirklichkeit der Glyphenfolge transkribiert wurde – eine Fehlerquelle, von der kein Mensch frei ist, der etwas Unverstandenes dokumentieren will.
EVA und die Probleme
Das Transkriptionsalphabet EVA hat leider ebenfalls Probleme, die Wirklichkeit der Glyphenfolge zutreffend abzubilden. Es beinhaltet etliche Annahmen vom Aufbau des Schriftsystemes, die natürlich auch falsch sein können, und aufgrund dieser Annahmen werden Glyphen des Manuskriptes auf maschinenlesbare Zeichen abgebildet. Alle folgenden Beispiele stammen aus der gut »lesbaren« Seite f22r, auf anderen Seiten lassen sogar bessere Beispiele finden. In der EVA-Transkription von Takeshi Takahashi »liest« sich diese Seite folgendermaßen:
pol olshy fcholy shol dpchy oty okoly daiin opchy s ocphy ol oiin shol o kor qokchol daiin otaiin cthor dain ckhydom qokol dykaiin okchy daiin cthol ctholo dar shain pchaiin ofchy daiin cfhy doroiin ypchol sy schor daiin ol daiin qokchy dar daiin chor oldor oky y choldchy y chokshchy ctheen kchol shol dsheor ska chdoly ytaiin ol otchy cphal dchor oty daiin ctholy qoky chotaiin chocthy doiiin dchor odaiin dain cthy ctheor oraiino kchol chor daiin cthoiin dchor chey qokol dy opchol oldam doiin yckhody qokchy oky otoldy yty dol or dachy daiin odchaiin cthy okchy kchy dchol daiin ydaiin dchor dydain qockhy ykalokain
(Diesen Auszug habe ich mit einem meiner Skripten aus meiner SQL-Datenbank der Transkriptionen erstellt, die Lokatoren für die Zeilen habe ich entfernt)
Die Transkription gibt nur einen sehr schwachen Eindruck davon, was sich wirklich auf der Seite f22r befindet.
Leerzeichen
Ein großes Problem bei allen Transkriptionen ist die sichere Erkennung von Leerzeichen. Diese sind keineswegs immer deutlich.
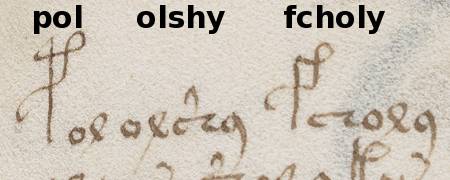
Während das Leerzeichen zwischen olshy und fcholy sehr deutlich ist, kann meiner Meinung nach pol.olshy eben so gut als pololshy gelesen werden. Ich verstehe allerdings, wie es zu dieser »Lesart« kommt, denn mit einer kurzen Abfrage der Datenbank kann ich feststellen…
mysql> select count(*)
from voy_word
where eva like '%olol%';
+----------+
| count(*) |
+----------+
| 44 |
+----------+
1 row in set (0.24 sec)
…dass über sämtliche Transkriptionen hinweg nur 44mal die Kombination olol innerhalb eines »Wortes« aufscheint, es handelt sich also um eine recht seltene Kombination von Glyphen. (Das häufigste derartige Wort ist übrigens olol, das 67mal in sämtlichen Transkriptionen erscheint.) Allerdings steht ol in 617 transkribierten »Wörtern« am Ende eines »Wortes«, und einige dieser »Wörter«…
mysql> select eva, count(*)
from voy_word
join voy_lineword on lword_word = word_id
where eva like '%ol'
group by eva
order by 2 desc
limit 10;
+-------+----------+
| eva | count(*) |
+-------+----------+
| ol | 1732 |
| chol | 1302 |
| shol | 626 |
| qol | 568 |
| cheol | 528 |
| dol | 386 |
| sheol | 346 |
| qokol | 307 |
| otol | 273 |
| sol | 259 |
+-------+----------+
10 rows in set (0.07 sec)
…sind im Manuskript recht häufig. (Auch diese Datenbankabfrage geht über sämtliche Transkriptionen und soll nur meine These von der Häufigkeit der Endung ol ein wenig untermauern.) Hier scheint das Unbewusste im Verlaufe der Transkription ein Muster aufgenommen zu haben und aus einer kleinen Lücke im Schriftfluss – die übrigens fast genau so breit ist wie die Lücke zwischen initialem p und folgendem o – ein wahrgenommenes Leerzeichen gemacht zu haben.
Sehr viele transkribierte Leerzeichen sind fraglich. Wer Analysen zu Annahmen macht, in denen die Leerzeichen eine Bedeutung tragen (etwa als Wort- oder Silbentrenner), ist gut beraten, wenn er die verwendete Transkription überprüft und gegebenenfalls nach Augenschein korrigiert, um gesichertes Datenmaterial zu haben.
(Am Rande bemerkt: Eine Datenbank mit den Transkriptionen ist selbst für mich, der ich sowohl den »Weg der tausend Tools« [Un*x] schätze als auch gern und schnell in Perl programmiere, immer wieder einmal nützlich. Auch, wer nicht mit Leichtigkeit SQL tippt, kann von einer solchen Datenbank profitieren, wenn er sich eine ODBC-Datenquelle einrichtet und ein Reporting-Werkzeug oder Microsoft Access verwendet. Mir allerdings ist alles, was Griffe zur Maus erfordert, ein Gräuel…)
Ver-daiin-t!
Die in EVA transkribierte »Wortendung« aiin ist recht häufig, und daiin ist das mit Abstand häufigste »Wort« mit dieser Endung. Die fünf häufigsten derartigen »Wörter« in der Transkription von Takeshi Takahashi sind:
mysql> select eva, count(*)
from voy_word
join voy_lineword on lword_word = word_id
join voy_line on line_id = lword_line
where line_trans = 'H'
and eva like '%iin'
group by eva
order by 2 desc
limit 5;
+---------+----------+
| eva | count(*) |
+---------+----------+
| daiin | 863 |
| aiin | 469 |
| qokaiin | 262 |
| okaiin | 212 |
| otaiin | 154 |
+---------+----------+
5 rows in set (2.72 sec)
Aber handelt es sich immer um das gleiche -iin? Oder handelt es sich um eine Annahme im Transkriptionssystem EVA, dass es sich immer um das gleiche -iin handele?
Nur einige Beispiele aus der recht klar »lesbaren« Seite f22r:

Hier fließen die in EVA als a, i und n transkribierten Komponenten klar zusammen, man ist auf dem Hintergrund des lateinischen Alphabetes fest geneigt, den »Text« als »odam dan« zu lesen.

Hier ist das n deutlich von den beiden zuvor zusammenfließenden, als i transkriberten Komponenten getrennt. Niemand weiß zur Zeit, ob diese Subtilität Bedeutung trägt, oder ob sie in der Eile des Schreibens entstanden ist. Aus der gleichmäßigen Tintenfarbe dieses Wortes scheint jedoch zu folgen, dass die Feder nicht in die Tinte getaucht wurde und dabei eine Unterbrechung des Schreibflusses entstand.
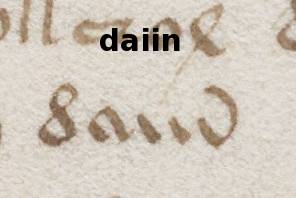
Hier ist zwar eine Verbindung zwischen dem a und dem ersten i erahnbar, aber es wird auch deutlich, dass die einzelnen i-Komponenten klar voneinander abgegrenzt geschrieben wurden. Das abschließende n weist einen klaren Abwärtsstrich auf, der nicht durch den Aufwärtsbogen zu einer Rundung verschliffen wurde.
Ver-daiin-tes Für und Wider
Obwohl niemand weiß, ob sich in diesen Feinheiten eine Bedeutung verbirgt, ist die Annahme der Bedeutungslosigkeit in die Definition des Transskriptionssystemes EVA eingeflossen.
Wir dürfen beim Betrachten dieser Bilder nicht vergessen, dass die Schrift im Manuskript klein ist. Wer einen Eindruck von den Größenverhältnissen bekommen möchte, besorge sich ein hochaufgelöstes Bild einer Einzelseite und drucke es auf eine DIN-A4-Seite aus, das ist fast die Originalgröße. Mit einem solchen Bild vor Augen wird verständlich, weshalb solchen Subtilitäten keine Bedeutung beigemessen wurde.
Aber…
Aber wenn ich mir selbst die Aufgabe stellen würde, einige unbedingt geheim zu haltende Notizen zu machen (das Manuskript ist doch verschlüsselt, nicht?) und keine modernen Hilfsmittel wie meinen Computer und GPG hätte, sondern mir ein Schriftsystem ausdenken müsste, denn würde ich den neugierigen und möglicherweise hingebungsvollen Leser nicht nur durch eingefügte Null-Zeichen, verschieden gestaltete Zeichen für häufige Buchstaben oder Laute und ein ungewohntes Schriftsystem verwirren, sondern ich würde auch dafür sorgen, dass verschiedene Dinge sehr ähnlich aussehen, um zusätzliche Verwirrung zu stiften. Viele Mittel hätte ich ja nicht zur Verfügung. Und ich würde bei alledem auch darauf achten, dass mir die Verschlüsselung nicht allzu viel Arbeit bereitet, denn ich würde ja in meinem Leben noch etwas anderes tun wollen, als meine Notizen zu verschlüsseln. Zum Beispiel das, worüber ich mir so viele Notizen mache. (Ob wohl viele nackte Frauen und außerirdische Drogenpflanzen darin vorkämen?)
Niemand sollte sich vom ersten Eindruck täuschen lassen. Schon gar nicht beim Voynich-Manuskript, das schon viele scharfsinnige Menschen auf der Suche nach einer Lösung zu beachtlichen Leistungen der Selbstverblendung geführt hat. Und jeder sollte sich bei einem derartigen Rätsel über alle im Vorfeld gemachten Annahmen klar sein, denn diese könnten falsch sein. Und ob dieses…
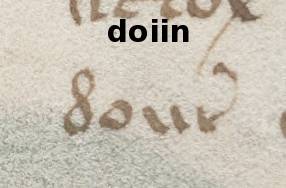
…doiin wirklich auf einem n endet, wie es die EVA-Transkription durch ihre eingeflossen Annahmen erzwingt, oder ob es nicht vielmehr ein r oder ein in EVA nicht auflösbares Mittelding zwischen n und r ist, gehört nicht zu den Dingen, über die ich eine sichere Aussage machen könnte. Aber ich bin mir sehr sicher, dass das gleiche Zeichen nach einem o als ein r transkribiert worden wäre, weil die »Wortendung« or (2255mal in Takahashis Transkription) nun einmal wesentlich häufiger als die »Wortendung« ir (590mal in Takahashis Transkription) ist. Wenn die wahrgenommene Ambiguität nicht anderes aufgelöst werden kann, denn werden eben unbewusst die bereits erkannten Muster eingefügt.
In wie großem Maße bei den Computeranalysen der Transkription wohl in Wirklichkeit die unbewussten Fähigkeiten des Transkriptors zur Mustererkennung untersucht werden? 😉
Das Problem betrifft nicht nur die »Wortendung« -iin, sondern in vielleicht noch größerem Maße die Glyphe sh, die es in einigen sehr verschiedenen Varianten gibt. Immerhin gibt es bereits Transkriptionen, die diesen Fakt sehr genau berücksichtigen, dabei sind die angewendeten Transkriptionsalphabete allerdings wesentlich schwieriger zu beherrschen.
Wie wurden die Zeilen geschrieben?
Auf der sehr klaren Seite f22r gibt es noch eine weitere Auffälligkeit. Aber um darauf einzugehen, muss ich zunächst auf etwas anderes hinweisen.
Zu den rätselhaften Eigenschaften des Manuskriptes gehört es nicht nur, dass die »Wörter« sehr regelmäßig gebildet sind (und dass dabei Ausnahmen von den Regeln über das gesamte Manuskript verstreut sind), sondern auch, dass die Zeilen im Manuskript eine interne Struktur zu haben scheinen. Currier schloss aus dieser Beobachtung, dass die Zeile im Manuskript eine Informationseinheit sein müsse.
Tatsächlich lassen sich, wenn eine große Menge transkribierten »Textes« untersucht wird, zum Ende der Zeile hin sowohl auf Wortebene als auch auf Zeichenebene signifikant unterschiedliche Häufigkeiten zählen. Diese Eigenschaft des »verdammten Manuskriptes« hat wohl nicht nur mich verwirrt. Ich habe sogar nach »Spuren von Lyrik« geforscht, ohne Anhaltspunkte dafür zu finden. Zu einem einfachen, mit wenig Hilfsmitteln durchgeführten Verfahren der Kryptografie wollte es gar nicht passen…
Vielleicht ist auf diesem Hintergrund der obere Absatz der Seite f22r interessant:

Ich finde hier die Schwankung der Tintenfarbe mitten in den Zeilen sehr auffällig. Hier noch einmal ein Detail, die schwarzen Linien sind natürlich von mir, aber das Bild des Manuskriptes wurde ansonsten nicht bearbeitet:

Um das in meinen Augen schon offensichtliche Detail noch etwas deutlicher zu machen, habe ich mit GIMP ein wenig an der Abbildung der Helligkeitswerte auf den Farbraum »herumgespielt«:

In der dritten Zeile ist es vielleicht gar nicht so deutlich und mag auf einer Selbsttäuschung beruhen (dafür macht dieses Manuskript anfällig), aber in den übrigen Zeilen ist es völlig offensichtlich, dass mitten in den Zeilen ein Unterschied in der Sättigung der Tintenfarbe eintritt. Da dieser Unterschied mit Ausnahme des »Wortes« chor immer auf Wortgrenzen zu fallen scheint und sehr stark ist und da beim »Worte« ch-or eine Verschiebung der Schreiblinie nach unten mittem im »Wort« aufzutreten scheint, entsteht nicht der Eindruck, es handele sich hier um eine Eigenschaft des Pergamentes.
Der Unterschied in der Tintenfarbe wirkt so stark, dass er sich kaum durch ein Neueintauchen der Feder in die unveränderte Tintenmischung erklären lässt. (Obwohl das natürlich auch möglich ist.) Vielmehr entsteht der Eindruck, als sei hier mitten in einer Zeile eine neu angemischte Tinte verwendet worden. Es kann natürlich sein, dass dieses Artefakt bei einer Restauration des Manuskriptes entstanden ist, die Seite weist ja auch oben rechts Spuren einer Beschädigung durch Feuchtigkeit auf.
Aber es kann ebenfalls sein, dass der Autor des Manuskriptes die jeweils zweite Hälfte der Zeilen nachträglich angehängt hat, und dass diese zweite Hälfte nur noch Null-Informationen enthält. Wenn er seinen eigenen Text lesen konnte, wird ihn ein solches Vorgehen nicht verwirrt haben – aber dafür verwirrt es uns, denn wir stehen vor den sehr rätselhaften Zeilenstrukturen des Manuskriptes…
So lange man sich vor allem mit Transkriptionen beschäftigt, fallen solche Dinge jedenfalls nicht auf.

Mittwoch, 14. Oktober 2009 9:49
Lots of good observations, great post! 🙂
Glen Claston has talked a lot about »half-spaces«, this might be a helpful turn of phrase for what you describe here.
Incidentally, I think the most likely poetry in the VMs is on f81r. 🙂
Mittwoch, 14. Oktober 2009 10:38
Einfach genial.
Sonntag, 18. Oktober 2009 23:22
Danke für den überaus hilfreichen Beitrag.
Dienstag, 3. November 2009 13:20
Was die Unterschiede der Tintenfarbe betrifft – Ich denke, man kann das tatsächlich relativ einfach mit dem neuen Eintauchten der Feder in die Tinte erklären.
Wenn du hinschaust, siehst du, dass die Tinte jeweils kurz vor der neuen Tiefschwärzung recht blass geworden ist, und ein neues Eintauchen ca. einmal pro Zeile scheint mir auch eine realistische »Tankfüllung« für eine Feder.
Sonntag, 8. November 2009 19:33
Ich schaue hier eindeutig zu wenig rein. Auch dies ist ein sehr wertvoller Beitrag.
Tatsächlich stellt die Transkription einer unbekannten Schrift uns vor einmalige Probleme. Wie sind leicht veränderte Formen einzelner Charaktere zu deuten? Wie soll man wissen ob es ein neues Zeichen, oder nur ein unklar geschriebenes bekanntes Zeichen ist?
Zu den Leerzeichen: Eva bietet die Möglichkeit ein ›unsicheres‹ Leerzeichen darzustellen, indem man einen Komma statt einen Punkt benutzt. Das erste Beispiel wäre dann:
pol,olshy.fcholy.