Die verborgenen Strukturen
Zu den bisherigen Versuchen, Voynich-artige Dokumente ohne Inhalt zu erzeugen, habe ich in diesem Blog mehrfach eine Andeutung über Strukturen im Voynich-Manuskript gemacht, die ich aber bislang nicht mit weiteren Daten belegt habe.
Zwar besteht bei den algorithmschen Reproduktionen bei oberflächlicher Betrachtung eine gewisse Ähnlichkeit zum Voynich-Manuskript, auch werden die typischen Wort-Strukturen des Manuskriptes durchaus überzeugend hervorgebracht, aber die Strukturen innerhalb der Zeilen und innerhalb der Seiten werden niemals reproduziert und wurden von den findigen Forschern gar nicht weiter beachtet. Alle Schlussfolgerungen, die auf einer optisch ähnlichen, aber strukturell unvollständigen mechanischen Reproduktion beruhen, sind fragwürdig – vor allem, wenn lauthals und reißerisch postuliert wird, dass es sich beim gesamten Manuskript um eine inhaltslose Nachricht, um einen Betrugsversuch eines talentierten Fälschers handelt.
Die verborgenen Strukturen sind im Manuskript vorhanden, recht deutlich, durch einfache Analysemethoden aufzudecken und bislang noch nicht mechanisch reproduziert worden. (Auch ich bin übrigens bei einigen einfachen Versuchen, Voynich-ähnliche Texte zu erzeugen, an dieser »Kleinigkeit« gescheitert.) Sie zeigen sich als eine zunächst nicht auffällige, aber statistisch sichtbare Feinstruktur innerhalb der Zeilen, der Absätze und innerhalb der Seiten.
Diese Strukturen sollen hier etwas beleuchtet werden, wobei ich nicht auf alle Einzelheiten eingehen werde. Insbesondere werde ich Strukturen innerhalb der Absätze nicht berücksichtigen.
Das Manuskript ist hoch strukturiert
Schon bei der Betrachtung einer Transkription fällt den meisten Menschen auf, dass die einzelnen Wörter im Manuskript nicht willkürlich gebildet sind. Die Strukturen innerhalb eines Wortes gehören zu den Eigenschaften, die so auffällig sind, dass sie kaum jemand übersieht – diese starken Strukturen innerhalb eines Wortes sind übrigens das deutlichste Argument gegen eine direkte Niederschrift einer heute in Europa gesprochenen Sprache, da keine europäische Sprache vergleichbare Strukturen aufweist.
So weit ich (der ich kein Experte für vergleichende Sprachwissenschaft bin) weiß, passen solche Muster nur auf Sprachen, die angesichts der europäischen Gestaltung der Illustrationen sehr unerwartet sind. Eine phonetische Niederschrift einer Sprache der tibeto-chinesischen Familie würde ähnliche Worteigenschaften hervorbringen, wenn der Ton der jeweiligen Silbe mitnotiert würde.
Im Voynich-Wort hat jede Glyphe ihren festen Platz. Einige Glyphen können nur am Anfang stehen, etwa q oder qo; andere sind typisch für das Ende eines Wortes, etwa iin, iir, dy oder im; wieder andere können an beliebiger Stelle im Wort erscheinen, etwa ch, sh, ee, s, d, p, f, t, k und die charakteristischen Kombinationen aus einem Gallow und ch wie ckh. Diese Regeln werden überlagert von einem zweiten Regelsatz, den ich als »harmonische Regeln« bezeichne; das Aufeinanderfolgen bestimmter Glyphen wird im Manuskript vermieden. Beide Regelsätze sind – um jeden Forscher zu verwirren – nicht völlig ohne Ausnahmen. Gegen die »harmonischen Regeln« verstoßen etwa 10 Prozent der Wörter, gegen die allgemeinen Regeln zum Wortaufbau verstoßen etwa 5 Prozent der Wörter im Manuskript – und diese beiden Gruppen von ungewöhnlich gebildeten Wörtern sind recht regellos im Text verteilt.
Trotz der vielen Ausnahmen: Die Regelmäßigkeit in der Struktur der Wörter ist eine grobe, der Anschauung entgegenkommende Tatsache, die jeder irgendwann bemerkt. Über diese auffällige Wortstruktur wird jedoch die Struktur der Wortverteilung in einer Zeile oft übersehen, obwohl sie sich durch einfachste Analysen offen legen lässt.
Für alle folgenden Analysen habe ich die Transkription von Takeshi Takahashi verwendet. Textuelle Besonderheiten wie Labels und Titel wurden herausgefiltert. Die beiden Perl-Skripten für die Verarbeitung stehen für eigene Experimente zum freien Download zur Verfügung.
Die Verteilung der Wortlängen in einer Zeile
Zunächst findet sich eine recht deutliche Struktur in den Zeilen. Die Wortlängen sind innerhalb einer Zeile nicht gleichmäßig verteilt, tendenziell erscheinen längere Wörter am Anfang der Zeile.
In den folgenden Diagrammen wird für die x-Achse jeweils der Wortindex aufgetragen (also die Information, um das wievielte Wort der Zeile es sich handelt), auf der y-Achse ist die durchschnittliche Länge des Wortes aufgetragen. Diese Analyse wird getrennt für den biologischen, pflanzenkundlichen und abschließenden Teil vorgenommen, sie wird ergänzt um die wenigen reinen Textseiten im Manuskript. Diese Auswahl wurde vorgenommen, weil die anderen Teile des Manuskriptes von ringförmigen Anordnungen des Textes geprägt sind, bei denen es willkürlich ist, bei welchem Wort die Zählung beginnt.
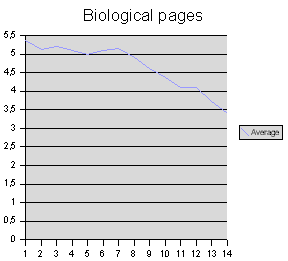
Zunächst die biologischen Seiten:
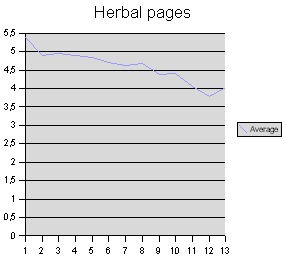
Jetzt die pflanzenkundlichen Seiten:
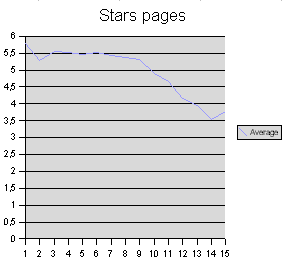
Jetzt die Seiten des abschließenden Teiles, die eine besonders deutliche Verteilung zeigen:
Und schließlich noch ein Blick auf die reinen Textseiten:
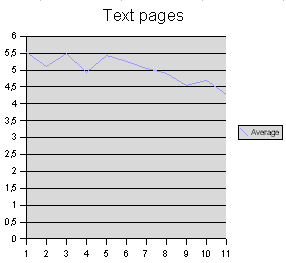
Das Muster in der Verteilung der durchschnittlichen Wortlängen ist recht deutlich, und es kann nicht auf einem Zufall beruhen. In einer Zeile erscheinen zum Anfang tendenziell die längeren (aus mehreren Glyphen bestehenden) Wörter, zum Ende hin nimmt die durchschnittliche Länge eines Wortes ab. Auffällig ist ferner, dass das zweite Wort einer Zeile tendenziell kürzer als das erste und dritte Wort ist, aber diese Erscheinung ist nicht so deutlich, als dass man eine verbindliche Aussage dazu machen möchte.
Wenn das Manuskript einen Inhalt hat, denn muss diese Verteilung der Wortlängen etwas mit der Form zu tun haben, in der dieser Inhalt niedergeschrieben wurde. Die Zeile im Voynich-Manuskript ist deutlich und nachweisbar strukturiert, die Wörter nehmen darin keine willkürliche Position ein. Jede Zeile ist als eine Informationseinheit zu betrachten. Jede Annäherung an den Inhalt des Manuskriptes muss diese Erscheinung in irgendeiner Weise erklären oder reproduzieren können, und diese Erklärung sind bisherige, dem Augenschein verhaftete »Lösungen« völlig schuldig geblieben.
So wenig einem die zählende Einsicht beim Verständnis weiterhilft, so sehr hilft sie doch dabei, vorschnelle Schlüsse einiger Autoren zu verwerfen. Eine direkte sprachliche Niederschrift menschlicher Sprache würde solche Strukturen in einem Fließtext nicht aufweisen, aber es ist sehr wohl möglich, dass solche Strukturen in lyrischen Texten aufscheinen. Wer eine Fälschung des Manuskriptes postuliert und hierzu ein Verfahren entwickelt, dass vergleichbare Texte erzeugt, muss sich auch Gedanken um die Strukturen in der Zeile machen.
Die Strukturen innerhalb einer Seite
Es gibt aber auch Strukturen innerhalb der Manuskript-Seite, die nicht ganz so deutlich sind, aber doch in eingen Teilen deutlich genug, um nicht durch einen Zufall erklärt werden zu können. Bei dieser Untersuchung werden Unterschiede zwischen den einzelnen Teilen des Manuskriptes auch am Text deutlich. Ich werde hier nur eine Struktur innerhalb der Seiten herausgreifen, weil sie sehr unerwartet ist.
Die auffälligsten Zeichen im Manuskript sind die so genannten »Gallows«, dies sind die großen, geschwungenen Glyphen f, p, t und k. Diese Glyphen geben einige Rätsel auf, da sie seltsame Ligaturen mit der ch-Glyphe bilden können, obwohl die Existenz einer solchen Ligatur bei der relativen Seltenheit dieser Zeichenfolgen überrascht. In den folgenden Diagrammen ist auf der x-Achse die laufende Zeilennummer auf der Seite aufgetragen, auf der y-Achse ist die durchschnittliche Anzahl der Gallows in diesen Zeilen aufgetragen. Diese Analysen sind für kleinere Zeilennummern aussagekräftiger, da dort mehr Text eingeflossen ist. Es kommt deshalb bei den hohen Zeilennummern zu deutlichen Fluktuationen.
Zunächst einmal die reinen Textseiten:
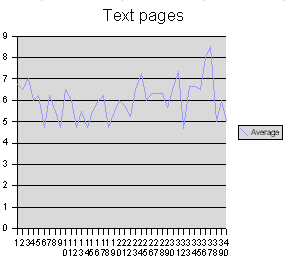
Recht ähnlich sieht dieses Diagramm für die Seiten des abschließenden Teiles aus:
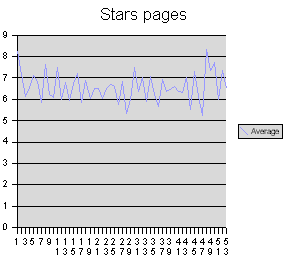
Bei alleiniger Betrachtung dieser Diagramme scheint es nicht den geringsten Zusammenhang zwischen der Häufigkeit der Gallows und der Position auf der Seite zu geben. Es scheint sich um mehr oder minder starke Schwankungen um einen Mittelwert zu handeln. Dieser Mittelwert liegt bei den reinen Textseiten bei 6 Gallows pro Zeile, bei den Seiten des abschließenden Teiles bei 6,6 Gallows pro Zeile. Die vergleichsweise starken Schwankungen der Verteilung für die reinen Textseiten erklären sich aus der Tatsache, dass es nur fünf reine Textseiten gibt, nämlich f1r, f58r, f58v, f66r, f85r1 – der abschließende Teil verfügt hingegen über 23 Seiten, so dass sich lokale Fluktuationen besser herausmitteln können.
Es gibt aber auch noch andere Teile im Manuskript, und da sehen die Diagramme völlig anders aus. Im biologischen Teil ergibt sich die folgende Verteilung:
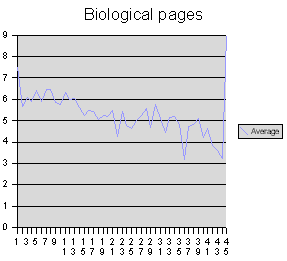
Hier zeigt sich schon eine sehr andersartige Verteilung, es gibt einen deutlichen Abwärtstrend in der durchschnittlichen Anzahl der Gallows für den unteren Teil des Dokumentes. Diese Struktur in der Verteilung der Gallows zeigt sich noch etwas deutlicher im pflanzenkundlichen Teil:
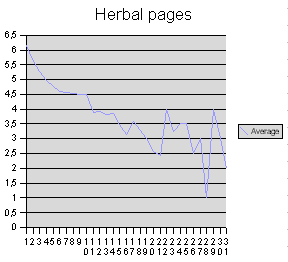
Es liegt also ein Zusammenhang zwischen dem mutmaßlichen, an Hand der Illustrationen naheliegenden Inhalt einer Seite und der Verteilung bestimmter Zeichengruppen auf der Seite vor. Dieser Zusammenhang ist nicht offensichtlich, er tritt unerwartet und überraschend bei einer Zählung in Erscheinung. Er ermöglicht es prinzipiell, die Art der Seiten nicht nur an Hand der Illustrationen, sondern auch an Hand einer Struktur des Textes auf dieser Seite zu erkennen. Es handelt sich vielleicht sogar um einen inhaltlichen Zusammenhang, dessen Bedeutung allerdings (mir noch) unklar ist.
Die ungleichmäßige Verteilung bestimmter Glyphen innerhalb des Kontextes einer Seite ist in jedem Fall schwer zu verstehen. Wenn man das Voynich-Manuskript als direkt niedergeschriebene Sprache deutet, würde eine solche Erscheinung bedeuten, dass bestimmte Laute oder Lautfolgen am Anfang eines Textes häufiger erscheinen als zum Ende hin; eine solche Erscheinung wäre eine sehr ungewöhliche lyrische Kunstform. (Gibt es Sprachen, in deren Lyrik so etwas üblich ist?) In jedem Fall zeigt sich durch einfaches Zählen der Gallows bei den biologischen Seiten schwach und recht deutlich bei den pflanzenkundlichen Seiten des Manuskriptes, dass dort jede Seite eine strukturierte Informationseinheit ist.
Abschließendes
Schon relativ einfache Analysen zeigen, dass das gesamte Voynich-Manuskript auf jeder denkbaren Betrachtungsebene (Zeichen, Zeilen, Seiten) hoch strukturiert ist. Die bisherigen Versuche, algorithmisch einen Voynich-ähnlichen Text zu erzeugen, haben nur Teile dieser Struktur reproduzieren können – leider wurden daraus weit reichende Schlüsse gezogen und publiziert.
Jede Erklärung für das Voynich-Manuskript muss die Gesamtheit der auftretenden Strukturen erklären. Es kann durchaus sein, dass dieses Manuskript keine »Nachricht« im herkömmlichen Sinne des Wortes enthält, aber wer das belegen will, indem er einen inhaltsleeren Text mechanisch konstruiert, der muss sehen, dass es mit der bloßen Erzeugung ähnlicher Glyphenfolgen nicht getan ist. Es müssen auch die leicht sichtbar zu machenden Strukturen innerhalb der Zeile und die teilweise auftretenden Strukturen innerhalb der Seite eines bestimmten Abschnittes reproduziert werden – und es muss eine vernünftige Erklärung gefunden werden, warum diese Strukturen in einem Kontext entstanden sind, im anderen hingegen nicht. Diese Aufgabe ist sehr viel schwieriger, als die von Gordon Rugg und seinen Nachahmern erstellten Demonstrationen für die Erzeugung Voynich-artiger Textfragmente, leider wird von solchen Autoren denn auch über diesen Problemkreis geschwiegen.
Wir versuchen jedenfalls weiter, die Botschaft zu lesen…

Mittwoch, 21. November 2007 1:54
Die Diagramme zur Zeilenstruktur lassen sich zum Teil (wenn nicht völlig) durch einen Effekt erklären, den man auch bei einem Zufallstext erwarten würde:
Bei Zeilen mit vielen Worten müssen die einzelnen Worte überdurchschnittlich kurz sein – nicht nur am Ende, sondern in der ganzen Zeile. Die rechte Seite der Diagramme zeigt also ausschließlich Zeilen, in denen per se viele kurze Worte enthalten sind.
Und umgekehrt enthalten Zeilen mit nur 9 oder 10 Worten entsprechend überdurchschnittlich viele besonders lange Worte, und ziehen erwartungsgemäß die linke Diagrammseite in die Höhe.
Um den Effekt herauszufiltern schlage ich vor, nur Zeilen mit gleicher Wortanzahl in jeweils einzelne Statistiken zu erfassen.
Wenn dann noch etwas von dem Effekt übrig bleibt, ist meine bevorzugte Theorie die, daß der Autor gegen Ende der Zeile, wenn der Platz knapp wurde, eher zu Abkürzungen neigte. Man sollte dafür mal nach Wort-Endungen forschen, die zum Zeilenende hin zunehmen.
Die Galgen-Verteilung ist hingegen in der Tat völlig unerwartet – und äußerst interessant.
Freitag, 30. November 2007 0:37
Die erwartete Längenverteilung bei Zufallstexten ist eine wirklich gute Anmerkung. Das ist eben das Problem, wenn man mit Skripten die Transkription verarbeitet – es macht blind für die einfachsten Erklärungen der auftrenden Effekte.
Wie viele wohl schon wegen solcher kurzschlüssiger Gedanken in die Irre geleitet wurden…
Freitag, 30. November 2007 4:23
Ich fürchte: Viele. Viele gute Köpfe. Ich sag nur: »cartes sur table«. 🙁
Du bist doch mit den Skripts offenbar versiert: könntest Du die nach unten abnehmende Galgen-Anzahl mal der Zeichen-Anzahl – oder besser: der Wort-Anzahl – derselben Zeilen gegenüberstellen? Ich hab da so einen Verdacht …
Freitag, 21. Februar 2014 13:53
[…] bekommen? Noch mehr eigenschaften? klick, klick, klick. Es ist einfach nur ein großer […]